

關於持續營運 (Business Continuity, BC) 與災難復原 (Disaster Recovery, DR) 這兩大詞彙,相信 IT 的從業人員經常耳聞,且思考如何在現有環境上實踐並維持可用性及靈活性。然而,這不只是 IT 相關團隊的發想、構思、甚至責任,企業內部對於商業行為的策略方向、管理階層的定位、及如何協同分工,這些具有管理特性面向的決策,都會直接影響 IT 從業人員所採用的執行方式。
當然,在真正執行這些災難復原的設計或演練前,還是需要依循這些「管理面」的政策與風險管理制度,而其中一項重要的指標原則,不外乎為企業內部能接受的 RTO 及 RPO:
- RTO (Recovery Time Objective),目標的復原時間:
指企業可容許服務中斷後到可正常回復到運作的狀態,中間需要耗時的時間成本。
- RPO (Recovery Point Objective),目標(最近的)還原點:
指企業可容許遺失的資料量的上限值。
例如,企業定義了當災難發生時,某關鍵系統的復原時間為 2 小時 (RTO)、最大可遺失資料點為 30 分鐘 (RPO),確定目標的基準值後,接續才是選擇以何種方式來達成此目標。
資訊科技日新月異,比起過往受限於實際地理位置或硬體設備資源等其它因素,在公有雲環境所提供的技術創新下,為企業除了在現有的選擇以外,帶來了更簡易、便利及高彈性的一種全新解決方案。以 Microsoft Azure 的其中兩項服務 Azure Backup 以及 Azure Site Recovery 為例,它們提供了企業所要求的 RTO 及 RPO 支持,也是企業普遍會選擇採用的災難復原方法之一。
Azure Backup
如同字面上所言,服務的本身性質在於針對「目標」做備份,即使企業內部目前尚無一套完整的災難復原計劃 (DR Plan),也必需達到最低的備援標準—「資料備份」,以防在任何預期外的狀況發生時,落於無法回復環境或最近資料狀態點的窘境。
Azure Backup 服務本身支援的備份目標範圍頗為廣泛,除了 Azure 環境的原生服務外,若地端環境許可安裝備份代理程式,亦可將資料備份至 Azure Backup 之存儲庫中,以提高在災難發生後的資料復原性;同時可透過生命週期的管控功能,將有實際上有效用的備份副本留存,再自動化刪除過時版本以節省備份成本。此外,透過 Backup Center 的集中管理,讓IT可以一目了然,並針對備份生命週期進行管控,如下示意圖(註1) :
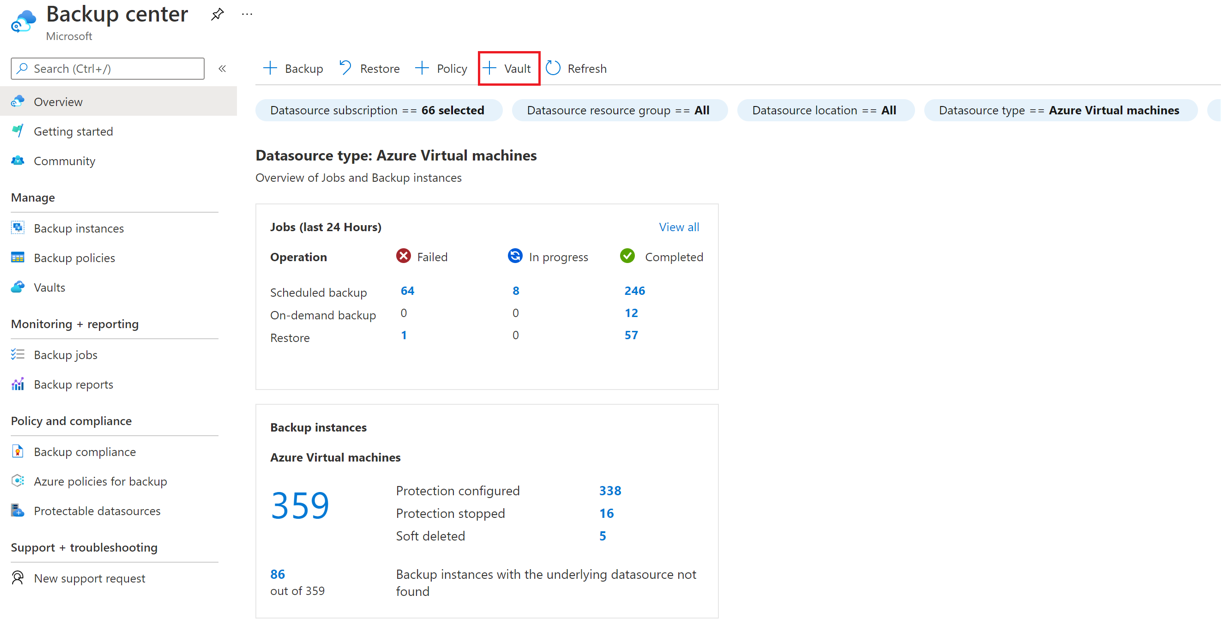
基於 Azure Backup 服務本質上的特性屬於「備份」,在 RTO 及 RPO 的考量上,除了依據企業定義出來的標準去設定外,也可以將它視為在整體 DR Plan 中的冷方案 (Cold Plan) 。所以在災難發生時,相對的 RTO 時間也會較熱方案 (Warm Plan) 來的長。
另一方面,在建立了基礎的備份機制後,針對一些關鍵系統 (Mission Critical Systems),企業無法容許有太長的 RTO 時間,這些系統需要即時的系統或站台復原,Azure Site Recovey 正是為了應付這種狀況而出現的一種技術方案。
Azure Site Recovery
Azure Site Recovery 服務本質上提供更即時的災難復原能力,讓企業可以在預期(排定演練)或非預期的情況下,實行異地轉移環境,大幅降低在災難發生時的停機時間,減輕業務上的經濟損失。
Azure Site Recovery 的技術原理,是將所需要保護的伺服器系統,透過代理程式執行複寫動作,複寫到公有雲,同時在指定的公有雲區域上佈建次要環境(或稱 DR 站台),以備在災難發生時執行自動、手動或混合的容錯移轉,讓使用者可繼續正常使用;待主要環境修復完成並可正常提供服務後,即可再次執行容錯移轉,把次要環境(或稱 DR 站台) 的系統服務移轉回到主要環境,進而達成完整的災難復原流程。
Azure Site Recovery 支持從地端複寫到 Azure 環境、跨地區的 Azure 複寫、以及從其他公有雲平台複寫到 Azure 環境。
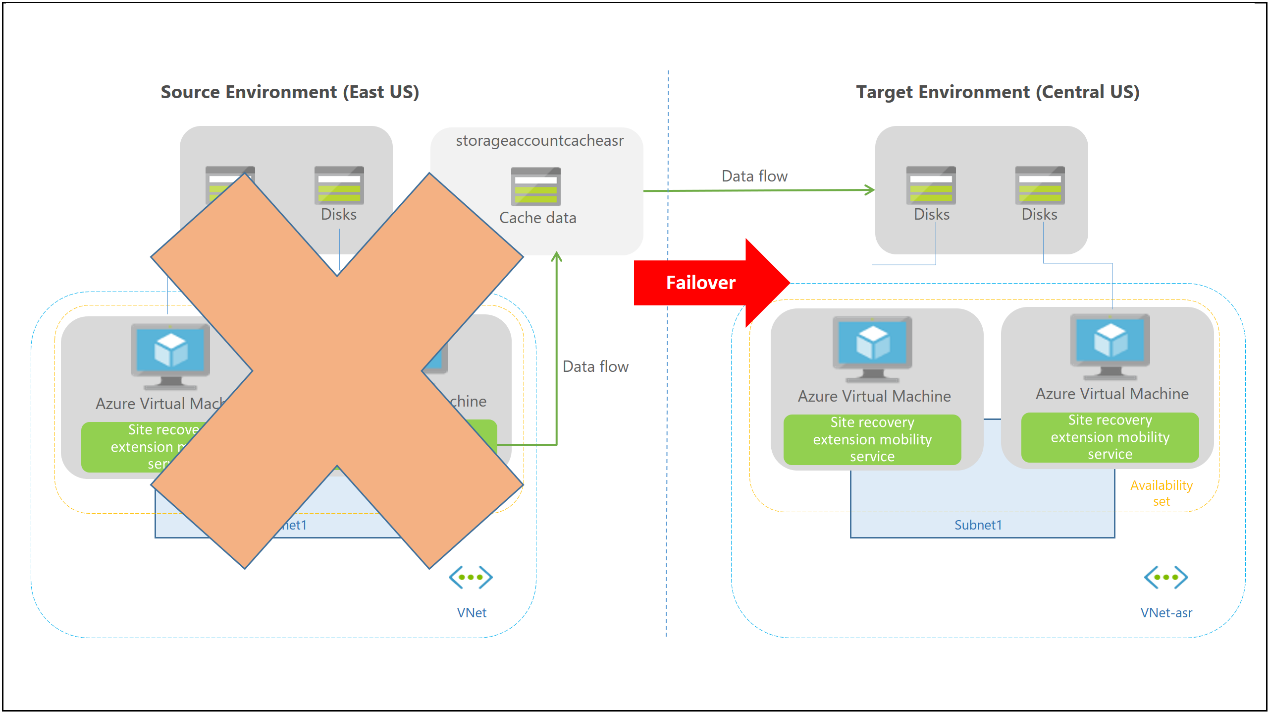
以跨地區的 Azure 災難復原情境為例 (註2):


3. 當災難發生導致主要區域 (East US) 服務中斷時,即可啟動容錯移轉機制至次要區域 (Central US) 並提供服務:
在現今經濟行為高程度倚賴資訊科技的情況下,持續營運與災難復原是每一家企業也需要考慮的永續策略之一。利用創新的技術方案,可以協助企業快速應對各種不可抗力的災難,以及降低從災難中所帶來的經濟損失。



